Streaming analytics refers to the processing and analyzing of data continuously, as opposed to regular batches. Streams are triggered by specific events as the result of an action or set of actions. Examples of these triggering events might include financial transactions, thermostat readings, student responses, or website purchases. Streaming analytics is also known as event stream processing.
In the streaming analytics paradigm, it can be helpful to think of data being streamed through a query. This is in contrast to the batch processing paradigm, where a query can be thought of as being submitted over an entire table or dataset. This is an embellishment and oversimplification, but helpful to illustrate the paradigm switch between streaming and batch processing.
As an example, imagine an instructor is accessing student understanding via some in-class online activity. We might be interested in sending a notification to the instructor’s tablet anytime a student is performing poorly, regardless of if the student has entirely completed the assessment. Thus, the instructor or a TA can provide immediate support to the student, while there is still time remaining in class. In this example, student responses are continually streamed through a query that returns TRUE anytime a student is scoring below 60% on the assessment, as long as the student has attempted at least 10 questions. If TRUE is returned, a notification is sent to the instructor’s table with additional information, such as exact missed problems and recommended intervention.
In this streaming example, the query can be thought of as always being active and waiting for new data to be sent through it. In constrast, a batch application might store the student responses in a database, and a scheduled query and application would send the instructor a summary email the following morning.
- Stream processing tools
- Stream processing engines
- The three v’s of streaming analytics
- Spark Structured Streaming
- Considerations
Stream processing tools
For streaming analytics, a stream processing tool is needed to manage the movement of the streaming data. Examples of these include Apache Kafka, Amazon Kinesis, and Google Cloud Dataflow. Apache Kafka might be the most common of these. Apache Kafka is almost always configured to process (move) data in parallel threads. Apache Kafka is typically configured to guarantee data will be delivered at least once or exactly once, but it does guarantee how that data will be sent. It might be sent over one thread or multiple threads. Because of this, data can be received late, out-or-order, or (sometimes) duplicated. This architecture is crucial in the context of streaming analytics and stream processing engines.
Stream processing engines
In addition to stream processing tools like Apache Kafka, a stream processing engine is needed to facilitate queries on top of streamed data. Examples of these include Apache Spark Structured Streaming (formerly Spark Streaming), Apache Flink (which is also a stream processing tool), Apache Storm, Spark SQL, and RapidMind. Because data can be received late, out-of-order, or duplicated, the streaming processing engine must be able to handle and reason about all of these.
The three v’s of streaming analytics
Occasionally discussed, the three V’s of streaming analytics refer to:
- volume - the (sometimes extremely large) amount of data being stored by many modern organizations
- velocity - the amount of data being streamed
- variety - the variety of data and formats being streamed (e.g., JSON, binary, raw text, images, etc.)
Spark Structured Streaming

Spark Structured Streaming (formerly Spark Streaming) is a stream processing engine built on the Spark SQL engine. Structured Streaming is scalable, fault-tolerant, supports event-time windows and stream-to-batch joins, and guarantees exactly-once stream processing. Internally, Structured Streaming processes queries using a micro-batch processing engine which can achieve end-to-end latencies as low as 100 milliseconds.
This post only provides a high-level overview of Spark Structured Streaming. For more details, please see the official documentation.
Fault tolerance
In the event Structured Streaming fails (i.e., a fault occurs), end-to-end exactly-once guarantees are ensured. Upon restarting, Structured Streaming will not duplicate or miss any processing. This is achieved via checkpoint and write-ahead logging. This is in contrast to some engines that ensure at-least-once guarantees under a failure, in which data will not be missed but may be duplicated.
When processing streaming data, Structured Streaming will generate a result table. Whenever this result table is updated, we might write it to external storage. Structured Streaming provides three output modes:
- complete - the entire result sable will be written to external storage
- append - only the new rows appended in the result table since the last trigger will be written to the external storage
- update - only the rows that were updated in the result table since the last trigger will be written to the external storage
Window operations on event time
Event time refers to the actual time the event occurred. This is in contrast to the actual time Spark Structured Streaming receives and processes the event, commonly referred to as processing time.
Aggregations over a sliding event time window are conceptually very similar to grouped aggregations, and are referred to as window operations.
For example, to monitor application uptime, we may be interested in counting the total number of student responses every 10 minutes across all sections of a large school.
Handling late data and watermarking
Late-arriving data can be handled via watermarking. Watermarks tell Structure Streaming how long to wait for late-arriving data, and require a threshold value.
For example, if we are counting the total number of student responses via a 10 minute sliding window, we could define a watermark threshold to be 5 minutes. If an event that occurred at 12:08 was received at 12:13, the event would be correctly included in the total number of student responses for the 12:00-12:10 interval. However, if the event arrived at 12:17 - which is past our 5 minute watermark threshold - the event would be dropped entirely and would not be included in our count at all.
Types of time windows
Spark Structured Streaming supports three types of time windows:
- tumbling (fixed) windows - a series of fixed-sized, non-overlapping and contiguous time intervals. An input can only be bound to a single window
- sliding windows - similar to the tumbling windows from the point of being “fixed-sized”, but windows can overlap if the duration of slide is smaller than the duration of window, and in this case an input can be bound to the multiple windows
- session windows - have a dynamic size of the window length, depending on the inputs. A session window starts with an input, and expands itself if following input has been received within gap duration. For static gap duration, a session window closes when there’s no input received within gap duration after receiving the latest input
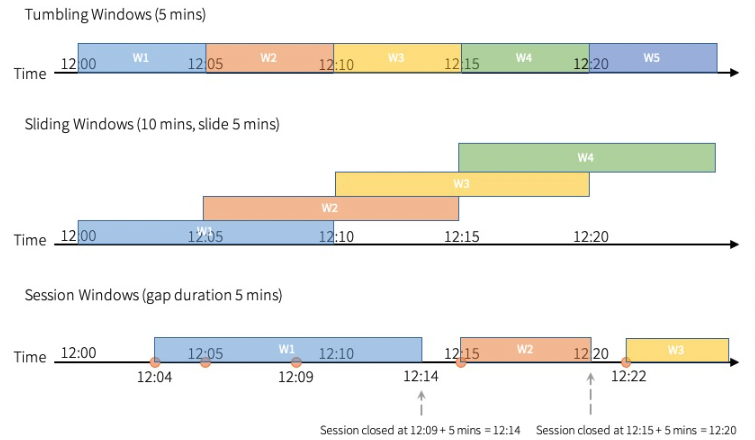 |
|---|
| Source: Apache Spark structured streaming programming guide |
Join operations
Structured Streaming supports a variety of join operations, including streaming-to-static data joins and streaming-to-streaming data joins.
Considerations
In general, streaming applications can require more planning and forethought than batch processing applications. For example, thought must be given to how to handle delayed data, and what amount of incoming data latency is acceptable.
Some other considerations for building and managing streaming applications are:
- Does the business problem actually require some action or information within a few seconds or few minutes? Does the current batch processing infrastructure support this need and is a streaming approach actually required? Could a batch processing job that runs every x minutes be a simpler approach for your problem?
- For different applications and problems, what degree of data latency is acceptable? Seconds? Minutes? If the streaming processing engine is slowed or disrupted, how detrimental will this be?
- Who will manage the streaming application when deployed in production? Will the management of the application be reasonable? How will your application handle delayed data? After what length of time is it appropriate to ignore delayed data?
- Does your application need both streaming data as well as statically stored data? Is the overall processing time to fetch data from multiple sources - and possibly perform joins - reasonable for your needs?
- Will your application be robust enough to handle differences and nuances in the incoming data stream?
- Does an existing data stream work for your needs? Does a new stream actually need to be created and managed?
- What monitoring is needed to monitor your data stream and overall application?