Big Header
Small Header
The structure of this post was influenced by the third chapter of An Introduction to Statistical Learning: with Applications in R by Gareth James, Daniela Witten, Trevor Hastie, and Robert Tibshirani.
\[\begin{aligned} Y = \beta_0 + \beta_1X_1 + \beta_2X_2 + ... + \beta_pX_p + \epsilon \end{aligned}\]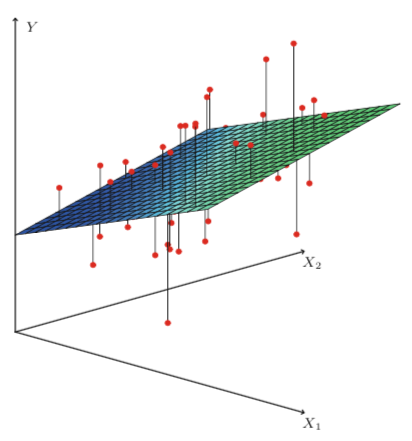 |
|---|
| Source: Gareth James, Daniela Witten, Trevor Hastie, Robert Tibshirani. An Introduction to Statistical Learning: with Applications in R. New York: Springer, 2013. |